
Product
Friday, December 5, 2025
Making FAIR Practical: Automated Dataset Assessment with F-UJI

FAIR in Theory, Difficult in Practice
Modern research workflows depend on datasets that are not only available, but also precisely described, machine-readable, and reusable. The FAIR (Findable, Accessible, Interoperable, and Reusable) principles provide high-level instructions for achieving that, but validating or checking manually if datasets are compliant with the FAIR principle is difficult to achieve, especially at scale.
Why Automated FAIR Assessment?
Manual FAIR review almost always breaks down at scale. Evaluating a dataset by hand means scanning the landing page, checking for a unique and persistent identifier like a DOI (Digital Object Identifier), confirming license visibility, digging through JSON-LD, and guessing whether the metadata covers provenance, distributions, or standardized schemas. Different reviewers make different assumptions, and results are rarely repeatable.
Automated assessment eliminates this ambiguity. A popularly used tool for automated assessment of FAIRness is F-UJI.
F-UJI as a FAIR Evaluation Tool
F-UJI is an automated evaluator designed to test whether a dataset’s metadata satisfies the FAIR principles. Instead of manually inspecting landing pages or guessing whether provenance is embedded correctly, F-UJI analyzes the metadata directly from authoritative sources, including:
- DataCite APIs
- schema.org JSON-LD on the landing page
- DCAT/Dublin Core fields
- linked provenance resources
You supply a DOI or a URL and F-UJI returns a structured report with:
- FAIR scores per metric based on FAIR metrics established by FAIR IMPACT
- Explanations of what succeeded or failed
- Machine-readable JSON output
- Clear guidance on how to improve missing elements
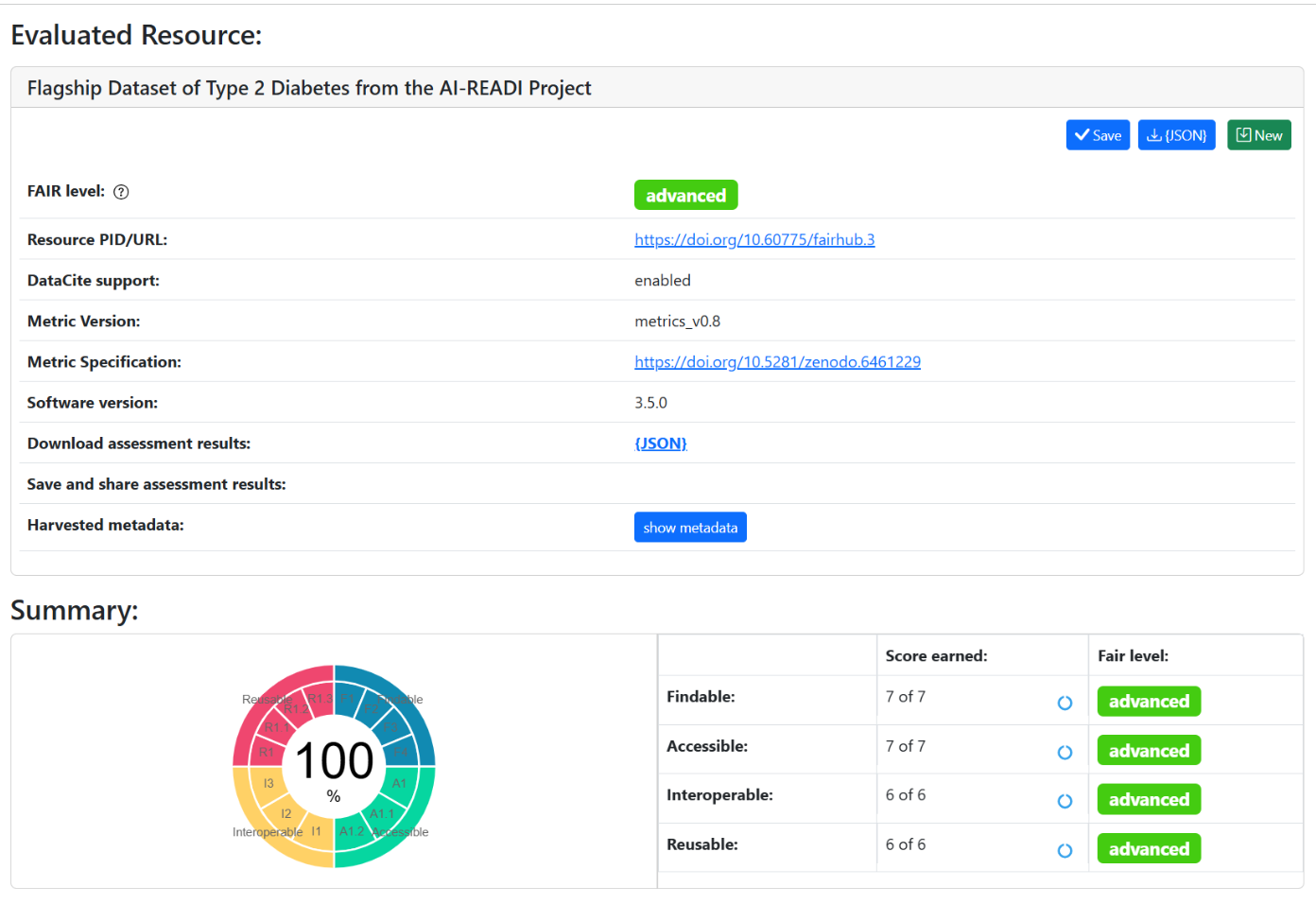
Our Case: Improving FAIR Scores Through AI-READI Metadata Optimization
When we first ran F-UJI using the AI-READI dataset DOI of our AI-READI dataset, the assessment returned a 67% FAIR score, with several Findable (F), Interoperable (I), and Reusable (R) metrics flagged as incomplete or missing.
Failing Checks Before Fixes
The initial F-UJI assessment surfaced several incomplete or missing metadata elements, primarily affecting the Findable, Interoperable, and Reusable categories:
- FsF-F4-01M — Metadata was not indexable by search engines (insufficient or incomplete JSON-LD)
- FsF-I2-01M — Semantic resources not properly declared in
@context - FsF-R1-01M — Metadata did not fully specify the content and characteristics of the dataset
- FsF-R1.2-01M — Machine-readable provenance information missing or incomplete
- FsF-R1.3-02D — Data not exposed in a community-recommended format (distribution metadata incomplete)
What We Changed
To resolve the failing F-UJI checks, we enriched the schema.org JSON-LD embedded on the dataset landing page. Instead of patching each metric in isolation, we added a single, coherent metadata block that simultaneously improved findability, interoperability, and reuse.
Enriched JSON-LD distribution metadata (FsF-F4-01M, FsF-R1-01M, FsF-R1.3-02D)
We introduced a structured distribution section using the DataDownload type so that both search engines and automated evaluators can reliably parse how the data can be accessed and reused.
Minimal structural example:
{
"distribution": [
{
"name": "...",
"@type": "DataDownload",
"conditionsOfAccess": "...",
"contentSize": "...",
"contentUrl": "...",
"description": "...",
"encodingFormat": ["..."],
"license": "..."
}
]
}
This single block carries several FAIR-relevant signals at once:
- indexable metadata for search engines (supporting FsF-F4-01M)
- a clear description of what the dataset contains and how large it is (supporting FsF-R1-01M)
- explicit encoding formats and community-recommended file types (e.g., DICOM), which contributes to FsF-R1.3-02D
Semantic Vocabularies and Provenance (FsF‑I2‑01M & FsF‑R1.2‑01M)
Both interoperability and provenance failures were resolved through a single enriched JSON‑LD injection inside the Vue script block.
Example structural outline of the additions:
{
"@context": [
"https://schema.org",
{
"pav": "...",
"prov": "..."
}
],
"@type": "Dataset",
"prov:wasDerivedFrom": {
"@id": "...",
"@type": "prov:Entity"
},
"prov:wasGeneratedBy": {
"@type": "prov:Activity"
}
}
The JSON‑LD block targets major structural fields:
- The
@contextnow declares standard vocabularies used across research metadata ecosystems, including schema.org, PROV‑O, and PAV. Declaring these namespaces ensures that all metadata terms map to registered, machine‑interpretable vocabularies. - The metadata now exposes PROV‑O properties that describe:
- what the dataset was derived from
- the activity responsible for generating it
All of these updates were implemented inside the Vue application by injecting an enriched <script type="application/ld+json"> block into the landing page, so the FAIR-aligned metadata is always rendered with the UI.
We ran the F-UJI assessment again after these changes and were able to see a 100% score.
Conclusion
F-UJI is a great tool for assessing automatically the FAIRness of a dataset at the metadata level, and easily identifying required improvements to increase the FAIRness of a dataset. After updating the JSON-LD, we reran F-UJI on the dataset. The FAIR score increased from 67% to 100%, and every previously failing metric passed. Together, these changes strengthened the dataset’s FAIR profile and ensured that the landing page now serves a complete, machine-interpretable metadata record that can be validated automatically on every release.
Acknowledgements
Some of the content in this post was refined with the help of ChatGPT’s writing tools.