
News
Friday, August 8, 2025
Reflections from ISMB and CoFest 2025: Advancing FAIR Research Software

This year marked the 33rd annual Intelligent Systems for Molecular Biology (ISMB) conference, hosted in Liverpool, England. As part of ISMB, the Bioinformatics Open Source Conference (BOSC) brought together researchers, developers, and open science advocates to explore topics in bioinformatics and open source software. This was our fourth year attending, and once again, I left inspired and energized.
From talks on analytic pipelines and toolkits to discussions on open data and FAIR practices, the conference reminded me why community-led open science is essential. One talk that particularly resonated with me, “Analytical Code Sharing Practices in Biomedical Research”, highlighted a persistent challenge: while data sharing is becoming standard, code sharing still lags behind. Although some journals enforce code availability policies, many only encourage it. This discrepancy underlines the importance of creating tools and guidance to help researchers make both their data and software FAIR: Findable, Accessible, Interoperable, and Reusable without barriers.
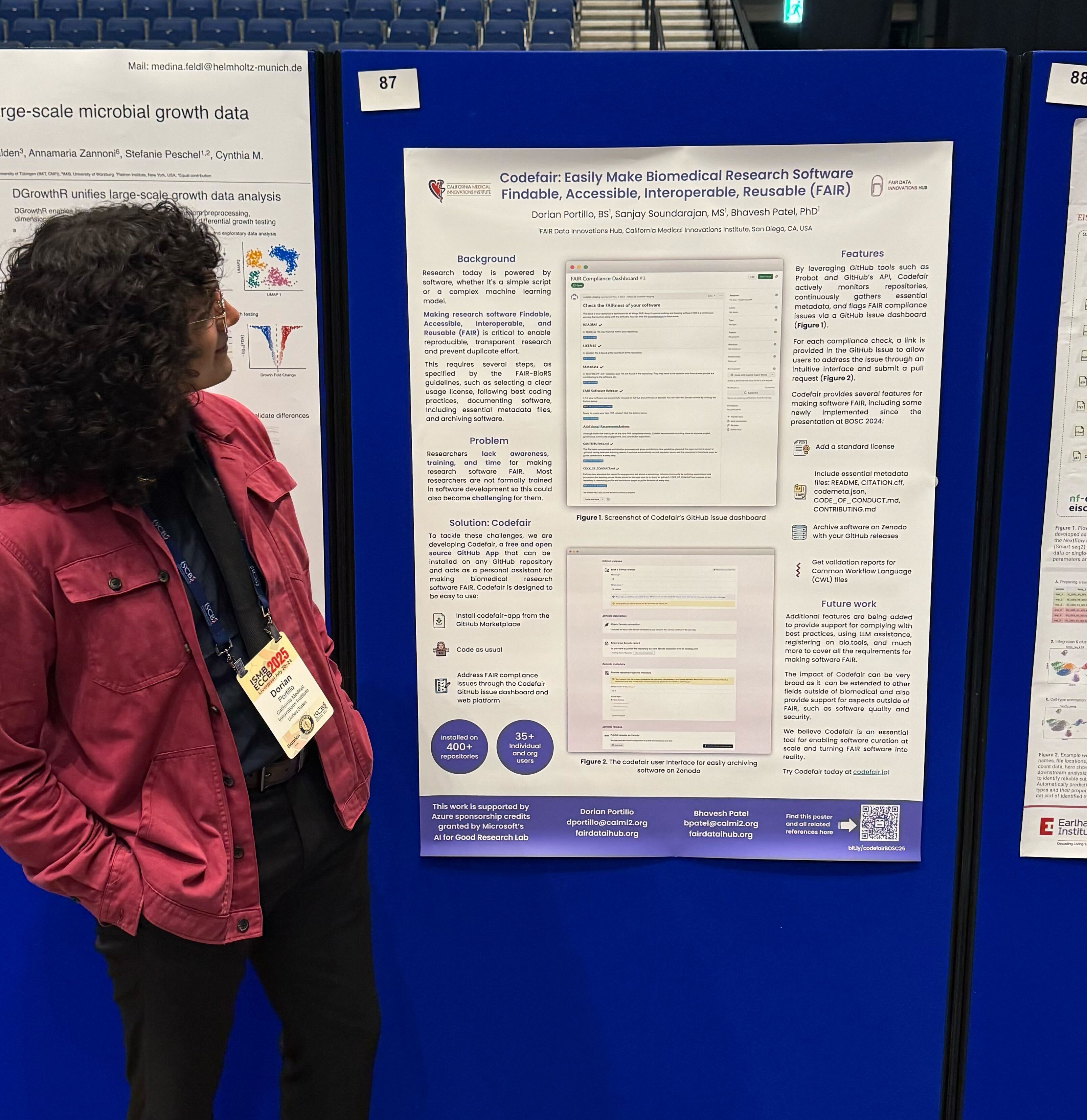
Presenting Codefair: Empowering Researchers with FAIR Tools
I presented Codefair, our GitHub App designed to help researchers streamline the process of making their research software FAIR compliant. The visual poster highlighted Codefair's latest features: supporting archival workflows with Zenodo, contributing metadata files such as CODE_OF_CONDUCT.md and CONTRIBUTING.md files, automated validations of Common Workflow Language (CWL) files, and a rehauled web interface to enable easier management of FAIR compliance across GitHub repositories and accounts.
On the same day, Bhavesh Patel presented virtually to introduce the Actionable FAIR4RS Task Force, an initiative under the Research Software Alliance (ReSA). The task force is translating the FAIR Principles for Research Software (FAIR4RS) into practical, actionable guidelines for everyday use. We’re thrilled to see the growing momentum behind making FAIR not just an ideal but a normalized practice.
CoFest 2025: Hacking on AI-Enhanced Documentation
Following the main conference, ISMB hosted CollaborationFest (CoFest) from July 23–24. CoFest is a two-day, high-intensity sprint where contributors collaborate on open science projects ranging from a variety of topics such as code, training materials, documentation and research outcomes. It was during CoFest that we explored the use of AI language models (LLMs) to improve the quality of README files in GitHub repositories.
I introduced a research hypothesis asking:
Can Language Models Improve README Files? A Comparative Study Using ChatGPT, Copilot, and DeepSeek

Why Focus on README Files?
README files are often the first point of contact for users of any software repository. Despite their importance, many READMEs are incomplete, inconsistent, or missing entirely. Quality varies widely being that there are no formal standards and only community recommendations.
Rather than providing entire repositories as input (which would be expensive and inefficient due to token costs), we focused on improving README content through iterations of smart prompting based on best practices. We used GitHub's official guidelines, the Awesome README collection, and community documentation standards as our reference point.

The Project: llm-readme-comparisons
The project involved comparing outputs from three AI models:
- ChatGPT 4.1 mini (Free Tier)
- Copilot (VSCode + web interface, GPT-4.1)
- DeepSeek
Each model was prompted with the same README content and guidance. Alejandra Paulina Pérez González and I assessed the results based on structure, clarity, adherence to best practices, and hallucinations (i.e., invented content). We iterated on our prompts to refine the outputs, aiming for a balance between conciseness and organization.
Key Observations
Model Behavior
- ChatGPT used emojis liberally, aiming for a friendly tone.
- DeepSeek emphasized clean formatting and structure.
- Copilot struck a balance between the two.
Prompt Limitations
Long README files often exceeded the free-tier token limit, leading to truncated outputs. Copilot's VSCode extension also flagged some content as public code and refused to proceed, requiring us to switch to the web interface.
Best Results Came From
README files that weren’t too long or too sparse. A “just right” README gave models enough to work with without hitting token limits or hallucinating new content.
Hallucinations
While minimal, hallucinations were present in some outputs. For example, an original README file mentioned the "CMU Computational Biology Hackathon (Mar 3–5, 2025)" and ChatGPT created a link for the phrase that led to the university's homepage instead of a specific event page.
Looking Ahead: Making AI-Powered Documentation Practical
We see potential in using AI to provide README improvements, but there are key areas for growth:
- Supplying short README files with metadata from GitHub's API for more context.
- Feeding longer READMEs in smaller sections to avoid truncation/token limitations.
- Improving prompts for general-purpose enhancement across diverse README formats.
- Leveraging model APIs for better control over input/output handling.
- Using advanced models with longer token capacities for deeper analysis.
Final Thoughts
CoFest offered a collaborative environment surrounded by like-minded people to test the feasibility of LLMs for documentation improvement. A task that may seem mundane but has real impact on usability and reproducibility. This work, while early-stage, contributes to a larger vision of enhancing the FAIRness of research software through both community effort and technological support such as Codefair.
If you're curious about the results, methodology, or want to explore the data yourself, the full project is available here: 🔗 github.com/slugb0t/llm-readme-comparisons
Stay tuned as we continue to explore how AI can responsibly be integrated into research workflows and open science infrastructure.


Acknowledgements
All images are credited to Nomi Harris, thank you for capturing these memorable moments. We are grateful for the support of the Microsoft AI for Good Lab and the welcoming BOSC community for creating an inspiring environment. Suggestions and wording improvements provided using ChatGPT.